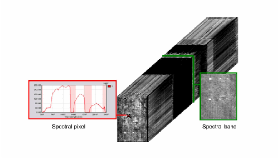
Figure 22.1: Illustration of an hyperspectral cube, spectral pixel and a spectral layer.
An hyperspectral image contains a collection of spectral pixels or equivalently, a collection of spectral bands.
An hyperspectral system 22.1 acquired radiance, each pixel contains fine spectral information fine that depends of:
Preliminary treatments allow to perform atmospheric correction for estimating a reflectance cube spectral by subtraction of information extrinsic of the scene (see also 12.2).
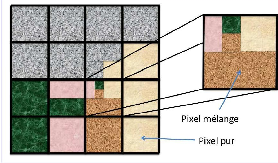
Reflectance information depends only of the materials spectral responses in the scene. When the mixture between materials is macroscopic, the linear mixing model of spectra is generally admitted. In this case, the image typically looks like this:
We notice 22.2 the presence of pure pixels, and pixel-blending. The LMM acknowledges that reflectance spectrum associated with each pixel is a linear combination of pure materials in the recovery area, commonly known as “”endmembers. This is illustrated in 22.3
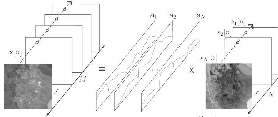
The “ left” term represents the different spectral bands of data cube. The “ right” term represents a “
product” between the reflectance spectra of endmembers and their respective abundances. Abundance band
of endmembers is image grayscale between
Many techniques of unmixing in hyperspectral image analysis are based on geometric approach where each pixel is seen as a spectral vector of L (number of spectral bands). The spectral bands can then be written as vectors.
By deduction of 22.3 et de 22.4, the LMM needs to decompose R as:
J is the number of endmembers and the number of spectral pixels I:
The unmixing problem is to estimate matrices A and S from R or possibly of Ẍ, an estimate of the denoised matrix signal.
Several physical constraints can be taken into account to solve the unmixing problem:
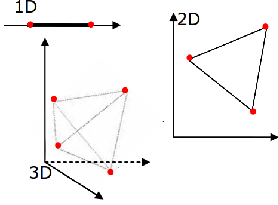
Recent unmixing algorithms based on the “property of simplex.” In a vector space of dimension
Hyperspectral cube of L bands, based on J endmembers, may be contained in a affine subspace of
dimension 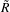
where each column of 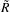 where the average spectrum is subtracted, generally estimated under
maximum likelihood. In the subspace carrying the column-vectors Z, endmembers spectra oare
associated to the top of the simplex. If the noise is negligible, the simplex circumscribed reduced
data.
where the average spectrum is subtracted, generally estimated under
maximum likelihood. In the subspace carrying the column-vectors Z, endmembers spectra oare
associated to the top of the simplex. If the noise is negligible, the simplex circumscribed reduced
data.
This property shows that the endmembers research are the vertices of a simplex that circumscribes the data. However, an infinity of different simplices can identify the same data set. In fact, the problem of unmixing generally does not have a unique solution. This degeneration can also be demonstrated by the formalism of the non-negative matrices factorization [3].
It is therefore necessary to choose the most physically relevant solution. All unmixing techniques based on this simplex property admit that the best solution is defined by the allowable minimum volume simplex, or the notion of volume is extended to all finite dimensions (possibly different from 3).
The more recent linear unmixing algorithms exploit the simplex property. It is possible to classify these methods into several families:
A first family of unmixing algorithms are based on research of the endmembers “among” data. This means that a minimum of one pure pixel must be associated with each endmembers. If this hypothesis is not verified, it will produce an estimation error of the endmembers spectra. The historical advantage of these algorithms are their low algorithmic complexity. The three best known are :
In addition to its success recognized by the community and very competitive algorithmic complexity, the endmembers estimation is unbiased in absence of noise (and when there are pure pixels).
Important elements on the operation of VCA:
A second family is composed of algorithms which are looking for the simplex of minimum volume circumscribing the data. Phase initialization consists in determining an initial simplex any circumscribing the data. Then, a numerical optimization scheme minimizes a functional, increasing function of the volume generalized, itself dependent of estimated endmembersin the current iteration. The optimization scheme is constrained by the fact that the data have remained on the simplex and possibly by constraints C1, C2 and C3.
Existing algorithms are:
Main differences between algorithms are:
These issues impact the computational complexity and the precision of the estimation.
Non negative matrix factorization algorithms (NMF for Non-negative Matrix Factorization). The purpose of this branch of applied mathematics is to factor a non-negative matrix, X in our case, into a product of non negative matrices: AS by minimizing a distance between X and AS and with an adapted regularization to lift the degeneration in an appropriate manner adapted to the physical problems associated with unmixing.
Algorithms of families 1 and 2 estimate “ only” the spectra of endmembers. The estimated abundance maps
held
Overview of algorithms and related physical constraints:
| VCA | MVSA | MVES | SISAL | MDMD |
C1 | mute | mute | mute | mute | hard |
C2 | mute | hard | hard | soft | hard |
C3 (additivity) | Mute (FCLS) | hard | hard | hard | soft |
simplex | Endmembers in the data | Circumscribed to data | Circumscribed to data | Circumscribed to data | Indirectly by “space” regularization |
The source code for this example can be found in the file
This example illustrates the use of the
The first step required to use these filters is to include its header files.
We start by defining the types for the images and the reader and the writer. We choose to work with a
We instantiate now the image reader and we set the image file name.
For now we need to rescale the input image between 0 and 1 to perform the unmixing algorithm. We use the
We define the type for the VCA filter. It is templated over the input image type. The only parameter is the number of endmembers which needs to be estimated. We can now the instantiate the filter.
We transform the output estimate endmembers to a matrix representation
We can now procedd to the unmixing algorithm.Parameters needed are the input image and the endmembers matrix.
We now instantiate the writer and set the file name for the output image and trigger the unmixing
computation with the
Figure 22.6 shows the result of applying unmixing to an
AVIRIS image (220 bands). This dataset is freely available at



Please refer to chapter 18, page 777 for a presentation of dimension reduction methods available in OTB.
By definition, an anomaly in a scene is an element that does not expect to find. The unusual element is likely different from its environment and its presence is in the minority scene. Typically, a vehicle in natural environment, a rock in a field, a wooden hut in a forest are anomalies that can be desired to detect using a hyperspectral imaging. This implies that the spectral response of the anomaly can be discriminated in the spectral response of “background clutter”. This also implies that the pixels associated to anomalies, the anomalous pixels are sufficiently rare and/or punctual to be considered as such. These properties can be viewed as spectral and spatial hypotheses on which the techniques of detection anomalies in hyperspectral images rely on.
Literature on hyperspectral imaging generally distinguishes target detection and detection anomalies:
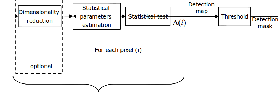
In 22.7, we introduce some notions that will be useful later. Anomaly detection algorithms have an image as input and consider a map serving as a detection tool for making a decision. A adaptive thresholding provides a estimated mask detection that we hope is the most similar possible as the ground truth mask, unknown in practice.
Two approaches dominate the state of the art in anomaly detection in hyperspectral images. Methods which use Pursuit Projection (PP) and methods based on a probabilistic modelization of the background and possibly of the target class with statistical hypothesis tests. The PP consists in projecting linearly spectral pixels on vectors wi which optimizes a criterion sensitive to the presence of anomalies (like Kurtosis). This gives a series of maps of projections where anomalies contrast very strongly with the background. But the automatic estimation of map detection have also major difficulties, including:
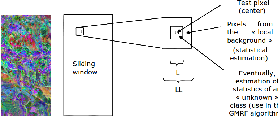
Algorithms described here are RX (presented in the first version in [114] and GMRF [122]. They are based on probability models, statistics and hypothesis tests and sliding window. These approaches consist in answering the following question : “The pixel (or set of neighboring pixels) tests looks like background pixels?”, by a process of test statistics. More fully, this approach requires:
Principle of RX and GMRF can be resume with 22.8.
An optional first step is to reduce the size of spectral data while maintaining information related to
anomalies. Then, the spectral pixels are tested one by oneturn (parallelizable task). The pixel test works on
a sliding window (see 22.9). This window consists of two sub windows, centered on the pixel test of
dimensions L and LL, with
Once all the parameters are estimated, a statistical test is performed and assigns a value
The RX algorithm is available in OTB through the